Why We Need To Talk About Schemas
Posted : 05-05-2016
In the Internet of Things there are many different ways of representing the same piece of data. When encoding efficiency and usability requirements conflict, can schemas help us deal with the confusion?
Of late, there has been an explosion in the number of 'Internet of Things' platforms - many of which are effectively some form of 'Data Logging As A Service'. These tend to be a variation on the Pachube concept, which pioneered the idea of using Web based technologies and RESTful APIs for IoT data aggregation. Since then, the use of RESTful HTTP based APIs has been augmented with publish / subscribe protocols such as MQTT and resource constrained protocols such as CoAP. However, the underlying idea of making IoT technology accessible to those with a Web development background remains.
JSON Is Taking Over the IoT
One legacy of this Web-centric approach to the IoT is that previous approaches to serialising data for transmission - such as ad-hoc binary data formats or XML - have generally been superseded by the use of JavaScript Object Notation (JSON). This was designed to be easy for humans to read and write and easy for machines to parse and generate, so that well designed JSON data formats are essentially self describing. By way of example, even though access to the Google Weave documentation is restricted to invitees only, the examples given in the following piece of slideware can be interpreted without making reference to any of the restricted API documents.
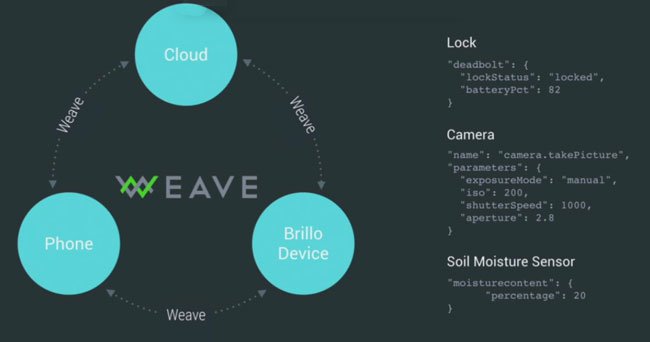
Although it is fairly easy for a human to read and interpret the underlying meaning of JSON data structures like these, it is unlikely that a machine could achieve the same result. Instead, it would have to be explicitly programmed to recognize the various attribute labels as having particular semantic meaning. Furthermore, different IoT platform vendors will typically chose different attribute labels to represent the same concepts. Although a human reviewing the content of a JSON data structure might be expected to infer the equivalence of attribute labels like 'lockStatus', 'isLocked' and 'lockedShut', a machine would have little chance. The situation is made worse by the fact that most platform vendors define their APIs using informal documentation, making it difficult to automatically factor out common functionality. Clearly some form of standardisation is required, which is why there are now almost as many IoT standards initiatives as there are IoT service providers.
The Efficient Serialisation Challenge
While the self describing nature of JSON based encodings was one of the original incentives for using it in IoT applications, it can impose an undesirable overhead when operating in resource constrained environments. The main problem is that while using meaningful attribute labels allows the encoding to be self describing, incorporating the associated text strings for each attribute instance makes the format very inefficient in terms of bandwidth utilisation.
An obvious step towards improving the encoding efficiency of JSON based representations can be made by minimising the length of the attribute label strings through the use of abbreviations. This is the approach that has been adopted for the SenML draft standard (draft-ietf-core-senml-00). For example, numerical value attributes are identified by the single character string "v", and baseline times by the two character string "bt". However, neither of these attribute labels can be interpreted without reference to the SenML standard - illustrating the inherent compromise between encoding efficiency and the ability to use self describing data formats.
Although SenML approaches the realistic limits of encoding efficiency for a JSON based format, the fact that JSON uses a text based encoding means that it is still much less efficient than a dedicated binary representation. Therefore the Concise Binary Object Representation (CBOR) defines a binary data format which can easily be translated to and from JSON. This allows JSON to be used when interoperating with Web-centric APIs, with CBOR being used to represent the same data on the resource constrained parts of the network. Indeed, this is the approach that has been adopted in more recent drafts of the SenML standard, where both JSON and CBOR formats are supported. A further optimisation is to allow the CBOR form of SenML to use integer 'tokens' as a more compact way of representing the attribute labels.
Introducing The Tokenising Schema
When implementing the proof of concept design as part of our previous Innovate UK funded project into 'Extending the Internet of Sensors to Remote Locations' we were faced with the problem of minimising the amount of bandwidth required to transfer the data over the satellite link, while still presenting it in a format which was suitable for access via a conventional Web API. The previous IETF work on SenML and CBOR provided a good starting point, even though the standard SenML format was not appropriate to our use case.
We adopted the idea of recoding JSON format data using CBOR and then 'tokenising' the text based attribute labels using an integer encoding, but wanted a more general way of describing the mapping between JSON based textual attribute labels and CBOR based integer label tokens. To do this, we looked at previous work on the proposed JSON Schema standard and decided to take a similar approach for defining valid JSON and CBOR data formats and the mappings between them. In practise this type of Tokenising Schema allows the data to be expressed in either expanded or tokenised form using JSON or CBOR formats.
By using the tokenising schema, it is possible to specify a formal definition of a given JSON data format that can be used for validation, as well as the associated mapping to the tokenised form. An example schema definition is given in the following code segment, which specifies a JSON object that contains an optional string property attribute named 'question' and a mandatory integer property attribute named 'answer'.
...
"exampleObject" : {
"type" : "object",
"tokenise" : true,
"properties" : {
"question" : {
"token" : 1,
"type" : "string"
},
"answer" : {
"token" : -1,
"required" : true,
"type" : "integer"
}
}
}
...
A valid JSON object which conforms to this schema is shown below. This is a conventional representation, where the full property attribute names are included in the encoding.
...
{
"question" : "What's the answer?",
"answer" : 42
}
...
A tokenisable object is indicated by setting the 'tokenise' flag for the schema and including the associated 'token' values for each property attribute. The result of tokenising the preceding JSON object using the example schema is shown below. Note that when expressing tokenised objects in JSON form, the integer token values need to be expressed as base 10 integer strings.
...
{
"1" : "What's the answer?",
"-1" : 42
}
...
The coding efficiency can be further improved by removing the need to store the integer token values. This can be achieved by mapping a JSON object onto an array during tokenisation. An example schema definition is given in the following code segment, which specifies a JSON object that contains an optional string property attribute named 'question' and a mandatory floating point property attribute named 'answer'. Note that the schema specifies the data type as being a 'structure', which indicates that an array based mapping should be used for the tokenised form.
...
"exampleStructure" : {
"type" : "structure",
"records" : {
"question" : {
"index" : 0,
"type" : "string"
},
"answer" : {
"index" : 1,
"required" : true,
"type" : "number",
"precision" : "double"
}
}
}
...
A valid JSON object which conforms to this schema is shown below. This is a conventional object representation, where the full record attribute names are included in the encoding.
...
{
"question" : "What's the real answer?",
"answer" : 42.0
}
...
A tokenisable data structure includes an array 'index' value for each of the specified records. The result of tokenising the preceding JSON object using the example schema is to insert the various record data items at the appropriate index positions of the tokenised array, as shown below.
...
[
"What's the real answer?",
42.0
]
...
Any data which is transmitted using this tokenised form can easily be expanded by applying the schema in order to generate the original JSON object. This provides a convenient way of expanding compact messages received from constrained sensor network nodes and converting them to self-describing JSON, as typically required by Web standards based IoT platforms. In the context of the Innovate UK proof of concept demonstrator, we implemented this conversion at the Satellite 'hub', so that the Internet facing side exposed a conventional JSON based API, while the bandwidth limited satellite link only had to transfer the tokenised CBOR data.
Further Development Ahead
We have already demonstrated the underlying viability of the tokenising schema approach as a proof of concept, and now need to expand upon the basic schema processing features. Our current internal development code is a Java library capable of parsing and serialising JSON and CBOR data, as well as performing validation and tokenisation using a subset of the planned schema definition syntax. We have also demonstrated interoperability with wireless sensor network CBOR data sources.
Our longer term objective is to be able to formally specify JSON and CBOR based SenML as a tokenising schema, as well as providing a formal definition of the tokenising schema format as a self encoded meta-schema. This should demonstrate that the tokenising schema format is powerful enough to support non-trivial use cases. We would then aim to release a complete Java based implementation as an open source library. As it is currently under active development, our current tokenising schema library is not yet ready for public release, but could be made available to consultancy customers who want early access. Please Email us at consult@zynaptic.com if this would be of interest.